
Period Over Period v Tableau | Mňamka #367
S porovnáním period over period se coby datoví detektivové potkáváme dnes a denně. V jednotlivých vizualizačních nástrojích je funkcionalita period over period řešená různými způsoby. Dnes se podíváme, jaké možnosti porovnání jednotlivých období nabízí Tableau. Po dobu práce s Tableau jsme narazili na několik přístupů, které si dnes představíme. Začneme jednoduchými řešeními na kliknutí, která jsou však méně ohebná, a zakončíme to řešením, které je velmi variabilní a umožňuje jedním filtrem vybrat předdefinovanou periodu, kterou chceme porovnat.
Quick Table Calculation
Jedná se o standardní řešení od Tableau. Najít lze celou řadu návodů - jeden z nich zde (Video od Penguin Consulting), další případně zde (Tableau Video).
Výhody
- Jednoduchá implementace
- Není výpočetně náročná
Nevýhody:
- První období nezobrazuje data, protože nemá s čím srovnávat
- Musím ve worksheetu zobrazit celé období
LOOKUP Funkce
Druhou možností je použít funkci LOOKUP(), která funguje pouze jako Table Calculation, tzn. provádí se pouze v rámci daného worksheetu (nikoli nad celým datasetem). Její funkce je v podstatě stejná, jako Quick Table Calculation. Stačí vydefinovat, "kam" se má funkce dívat. Detailní manuál najdete zde.
Výhody / nevýhody jsou stejné jako v případě Quick Table Calculation (ostatně Quick Table Calc je v podstatě pouze UI na tento druh funkcí). LOOKUP funkce se ale dá také použít na skrývání části vizualizace, kterou nechceme vidět.
Master / Slave Dataset
Další z možných technik je využít Master / Slave dataset, v Tableau nazývaný jako data blending.
Pojďme si tuto techniku vysvětlit na příkladu. Máme tabulku s transakcemi a chceme nastavit YoY porovnání. Tabulka obsahuje fakt price a order_date.
- Krok 1: V ETL (nebo v Tableau pomocí calculated fields) upravíme tabulku tak, že přidáme sloupec order_date_next_year, kde přičteme 1 rok k order_date.
- Krok 2: Následně v Tableau nad touto tabulkou definujeme 2 datasety (pro získání druhého datasetu stačí udělat kopii dané tabulky). Jeden dataset bude obsahovat sloupce price a order_date (transations_this_year), druhý bude obsahovat sloupce price (můžeme nastavit alias - přejmenovat - na price_last_year) a sloupec order_date_next_year, s aliasem (přejmenováno na order_date) (transactions_last_year).
- Krok 3: Následně použijeme blending, jehož součástí je transactions.order_date -> transactions_last_year.order_date.
- Krok 4: Nyní můžeme např. vytvořit metriku SUM([price]) / SUM([price_last_year]).
Výhoda
- YoY porovnávání probíhá na úrovni dat a nikoli vizualizace, takže lze filtrovat např. na jediný den a vše funguje ok.
Nevýhoda
- Výpočetně náročné díky použitému blendingu. Pokud je použito na dashboardu vícekrát, může být výkon dashboardu zásadně degradován.
Custom filter s předdefinovaným obdobím (WTD, MTD, YTD,...)
Výhodou tohoto řešení je variabilita období, které lze jedním filtrem vybrat.
Za základ jsou považovány tyto předdefinovaná srovnání, ale v podstatě je lze jakkoliv doplnit/rozšířit (např. o last 30 days, Month to date YoY,...):
- Week to date - data za tento týden do dneška vs. data za stejné období minulého týdne
- Month to date - data za tento měsíc do dneška vs. data za stejné období minulého měsíce
- Year to date - data za tento rok do dneška vs. data za stejné období minulého roku
- Moving annual total - data za minulých 12 měsíců vs. data za stejné období před tím
- Last month - data za minulý měsíc vs. data za stejný měsíc v minulém roce
Postup:
- Krok 1: Vytvořím parametr, který obsahuje období, která chci filtrovat, spolu s values (INT), která použiji v dalším calculated fieldu.
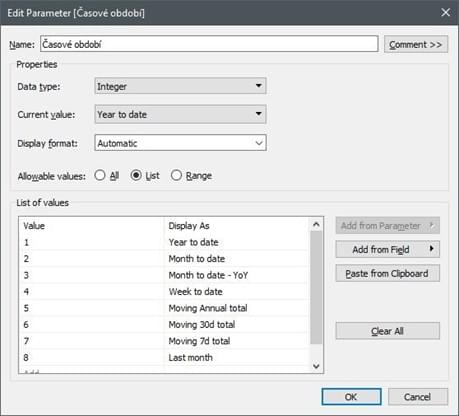
- Krok 2: Vytvořím jednotlivé calculated fields pro každý druh periody z kroku 1 (viz níže), kde definuji, jaké období s kterým porovnávám (analogicky upravím pro rozdíl dnů/týdnů/měsíců...).

- Krok 3: Vytvořím calculated field, který vybírá metriku na základě vybraného období.

- Krok 4: Požadované metriky, které mají porovnávat období upravím následovně: (Current Period = 2, Previous Period = 1).

- Krok 5: Vložím filtr a metriky do dashboardu and that's it! :)
Případný detail zde: The Ultimate Guide to Year-over-Year Comparisons in Tableau
Závěr
Je zřejmé, že přístupů k zobrazení period over period je v Tableau několik. Při rozhodování, který z nich použít je potřeba brát v úvahu potřebu variability řešení, jednoduchost implementace a v neposlední řadě také výslednou performance (rychlost načítání) dashboardu. Používáte v Tableau nějakou další techniku pro zobrazování period over period? Podělte se s námi.
Pokud máte nějaké otázky, připomínky či komentáře, budu rád, když mi napíšete.
Tomáš

Tomáš Dědek
Datový detektiv
Líbí se vám článek? Ochutnejte naše mňamky.

AI Audit: Když chcete vědět, kde ve firmě AI dává smysl (a kde ne)| Mňamka #552
Znáte to – CEO se vrátí z konference a ptá se „a my s tou AI něco děláme?“, IT má pět různých nápadů, co by se dalo zkusit, marketing chce chatbota, a ve skutečnosti nikdo přesně neví, co z toho má smysl a kde začít. AI audit je pro firmy, které nechtějí jen naskakovat do vlaku, ale chtějí vědět, kam ten vlak vlastně jede. Typicky to jsou střední a velké společnosti, které už mají digitalizované procesy a nějaká data – a teď zjišťují, že „AI strategie“ nemůže být „zkusíme, uvidíme“.

Metadata management: Proč je katalog dat nutností, ne luxusem | Mňamka #551
“Metadata jsou data o datech.“ - tohle, když od nás slyšeli profesoři na VŠE (Vysoké škole ekonomické), rovnou nás poslali ze zkoušky domů s tím, že se za nedlouho opět uvidíme. 😀Ona je to sice pravda, ale nejde ani tak úplně o jednu pevně stanovenou “definici” jako spíš o tu samotnou podstatu. Díky metadatům organizace chápe svá data, své systémy i pracovní postupy, protože metadata popisují, vysvětlují a usnadňují vyhledání, použití a správu jakéhokoliv datového zdroje.

7 nejběžnějších promptů datového analytika a inženýra | Mňamka #550
Datoví analytici a inženýři tráví spoustu času rutinními úkoly – od čištění dat až po ladění kódu. Umělá inteligence dnes dokáže část téhle práce výrazně urychlit. Klíčem je dobře napsaný prompt – zadání, kterým AI přesně řeknete, co má udělat. Podívejme se na 7 promptů, které se v praxi hodí nejčastěji.
