
Datové sklady, jezera a lakehouse: Jak vybrat správnou architekturu pro správu dat? | Mňamka #533
Datové sklady, datová jezera a Lakehouse architektury: Ponořme se do hlubšího prozkoumání
Svět správy dat prošel rychlým vývojem, který je poháněn rostoucí potřebou zpracovávat a analyzovat obrovské množství dat v reálném čase. Firmy, které chtějí porozumět svým datům, narazily na různé architektury – datové sklady, datová jezera a nyní i tzv. lakehouse – které nabízejí různé možnosti pro ukládání a správu dat.
Tento článek se zabývá těmito třemi architekturami, porovnává jejich výhody a nevýhody a podrobněji se zaměřuje na lakehouse, nejnovější inovaci, která se snaží řešit problémy z dřívějších systémů.
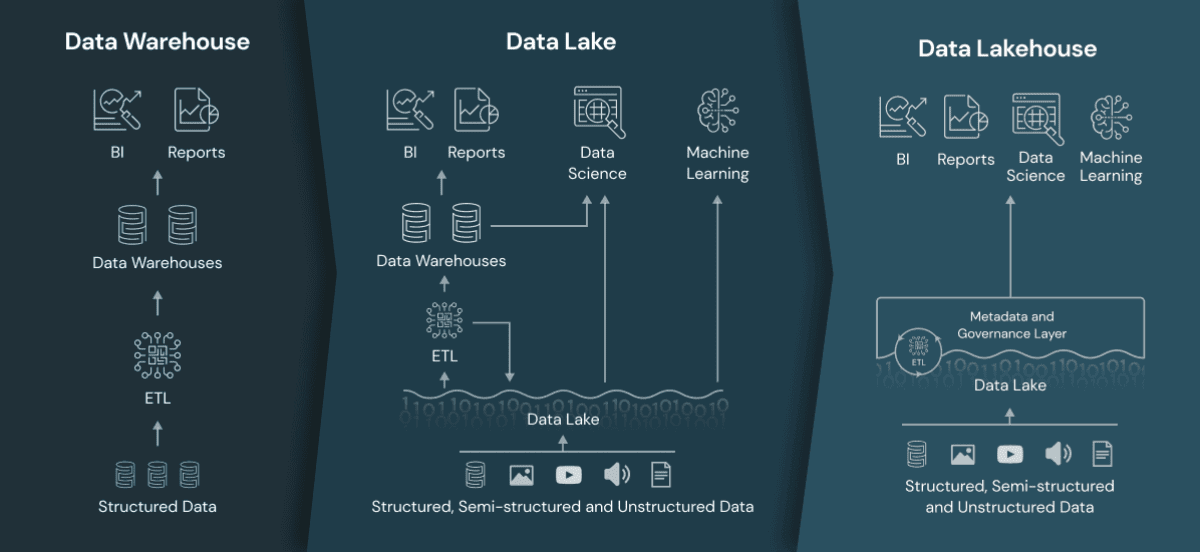
Image source: Databricks
Datové sklady: Strukturované, spolehlivé, ale potenciálně drahé
Přehled a časová osa: Datové sklady existují od 80. let, kdy byly navrženy především pro analýzu strukturovaných dat z provozních databází. Jejich popularita vzrostla v 90. letech s rozvojem business intelligence (BI) a reportovacích systémů. Původně šlo o lokální řešení jako Teradata a Oracle, ale s rozvojem cloud computingu získaly na oblibě cloudové datové sklady, jako je Amazon Redshift, Snowflake a Google BigQuery.
Jak fungují: Datové sklady jsou optimalizovány pro strukturovaná data a vyžadují tzv. schema-on-write, což znamená, že data musí být zpracována a vyčištěna před vstupem do skladu. To zajišťuje rychlé dotazování a podporuje BI nástroje, což je ideální pro organizace, které potřebují analytiku na konzistentních a čistých datech. Cloudové datové sklady navíc umožňují škálovat úložiště a výpočetní výkon, což poskytuje větší flexibilitu a efektivitu nákladů oproti tradičním řešením.
Výhody:
Vysoký výkon: Datové sklady excelují v dotazování na strukturovaná data pomocí optimalizovaných SQL systémů.
Integrita dat: Zajištění kvality a spolehlivosti dat díky schema enforcementu.
Podpora pro BI: Snadná integrace s tradičními BI nástroji pro reporting a dashboardy.
Nevýhody:
Vysoké náklady: Náklady na údržbu klasických datových skladů mohou být vysoké, zvláště při škálování dat.
Omezená flexibilita: Fungují dobře se strukturovanými daty, ale mají potíže s polostrukturovanými a nestrukturovanými daty jako obrázky nebo logy.
Závislost na ETL procesech: Data musí projít ETL (Extract, Transform, Load) procesy, což přidává složitost a časová zpoždění.
Data Lake: Flexibilita a škálovatelnost, ale riziko „datových bažin“
Přehled a časová osa: V polovině 2000s začaly organizace generovat mix strukturovaných a nestrukturovaných dat v bezprecedentním rozsahu. Datová jezera s flexibilním přístupem schema-on-read byla navržena, aby umožnila ukládání všech typů dat v původní podobě. Byly vyvinuty systémy jako Apache Hadoop’s HDFS (Hadoop Distributed File System) a později cloudové úložiště jako AWS S3 a Azure Data Lake pro uchovávání těchto velkých datových sad.
Jak fungují: Datové jezero ukládá vše – strukturovaná, polostrukturovaná a nestrukturovaná data – bez nutnosti definice schématu předem. Tato flexibilita je ideální pro velkoobjemovou analytiku, strojové učení a zpracování dat v reálném čase. Nedostatek správy a organizace dat však často vedl k tomu, že se datová jezera mění na „datové bažiny“, kde se špatně spravovaná data stávají obtížně využitelnými.
Výhody:
Škálovatelnost: Datová jezera mohou ukládat petabajty různorodých dat s minimálními náklady, zejména při použití cloudového úložiště.
Flexibilita: Není třeba předem definovat schéma, což umožňuje ukládání dat v jejich původní podobě.
Víceúčelovost: Datová jezera mohou využívat data vědci, inženýři i analytici pro různé pracovní úkoly, včetně strojového učení a analytiky v reálném čase.
Nevýhody:
Problémy s řízením dat: Bez schématu nebo správy riskují datová jezera proměnu v datové bažiny, kde se kvalita dat zhoršuje.
Složitost dotazování: Dotazování a analýza neupravených dat mohou být pomalejší a méně efektivní.
Absence transakčních záruk: Datová jezera přirozeně nepodporují ACID transakce, což je činí méně spolehlivými pro klíčové aplikace.
Data Lakehouse: Spojení toho nejlepšího z obou světů?
Přehled a časová osa: Lakehouse je nejnovější inovací v oblasti datových architektur, která se objevila na začátku 2020s. Kombinuje škálovatelnost a flexibilitu datových jezer se spolehlivostí a výkonem datových skladů. Lakehouse, který představily společnosti jako Databricks se svou technologií Delta Lake, se snaží řešit hlavní problémy tradičních skladů a jezer, zejména proměnu datových jezer v „datové bažiny“ kvůli nedostatku správy a struktury.
Jak fungují: Lakehouse využívá metadatovou vrstvu na vrcholu levného úložiště (např. AWS S3), která umožňuje ACID transakce, indexaci a prosazení schématu. Tím poskytuje Lakehouse spolehlivost datového skladu a zároveň flexibilitu datového jezera. Díky podpoře otevřených formátů souborů, jako jsou Parquet a ORC (Optimized Row Columnar), je navržen pro bezproblémovou práci s různými analytickými a strojově-učícími pracovními úkoly.
Otevřené formáty souborů:
Apache Parquet a ORC jsou mezi nejčastěji používanými formáty v lakehouse architekturách, protože jsou sloupcovými formáty úložiště, což znamená, že data ukládají efektivně a jsou optimalizovaná pro analytické dotazy. Parquet je například velmi efektivní, pokud jde o úložiště i výkon dotazů, což vysvětluje jeho rozšířené použití v systémech jako Apache Spark a cloudových platformách.
Další formáty jako Delta (Databricks) a Iceberg (Netflix/Apache) přidávají další vrstvy transakční integrity, indexace a časového cestování (verzování dat), což je činí ideálními pro lakehouse architektury, které hledají spolehlivost dat.
Řešení problému „datových bažin“: Lakehouse řeší problémy s řízením dat pomocí nástrojů jako katalogy dat a prosazení schématu. Tyto funkce zajišťují, že data vstupující do lakehousu jsou dobře dokumentovaná, dostupná a udržitelná. Katalogy dat jako Unity Catalog (Databricks) nebo open-source řešení jako Apache Hive Metastore poskytují další vrstvu správy, která podnikům umožňuje vyhnout se problému datových bažin a zároveň umožňují všestrannější, rychlejší a spolehlivější přístup k datům.
Výhody:
Jednotná architektura: Snižuje redundanci a zjednodušuje datový stack, eliminuje potřebu oddělených datových jezer a skladů.
Podpora různých pracovních úloh: Ideální pro analytiku i strojové učení.
Efektivita nákladů: Využívá levné úložiště a zároveň udržuje vysoký výkon dotazů.
Správa: Kombinuje mechanismy řízení z datových skladů s flexibilitou jezer.
Nevýhody:
Složitost: Počáteční nastavení může být náročné a přechod z existujících architektur může vyžadovat značné úsilí.
Relativní nezralost: Lakehouse architektury se stále vyvíjejí a ne všechny platformy dosáhly úrovně vyspělosti tradičních datových skladů, pokud jde o ekosystém a podporu komunity.

Image source: Starburst
Microsoft Fabric a moderní datová krajina
Microsoft Fabric, nováček v oblasti správy dat, integruje mnoho z těchto konceptů a nabízí jednotnou analytickou platformu, která kombinuje datové inženýrství, integraci a analytiku. Platforma vybudovaná na Azure podporuje lakehouse architekturu využitím OneLake, cloudového úložiště od Microsoftu, a obsahuje pokročilé analytické a BI nástroje, jako je Power BI. Cílem Fabric je zjednodušit celý datový tok a nabídnout komplexní řešení, které sníží složitost spojenou se správou oddělených systémů pro jezera, sklady a pokročilou analytiku.
Závěr
Evoluce od datových skladů přes datová jezera až po lakehouse architektury představuje pokračující úsilí o vyvážení flexibility, nákladové efektivity a správy v oblasti datové infrastruktury. Zatímco datové sklady zůstávají nezbytné pro strukturované dotazy s vysokým výkonem a datová jezera jsou ideální pro masivní, nestrukturované datové sady, lakehousy si vytyčují nové pole tím, že spojují oba přístupy do jednotné architektury. S rostoucím zájmem firem o lakehouse lze očekávat další inovace zaměřené na optimalizaci správy, nákladů a víceúčelového využití. Vstup Microsoft Fabric na trh naznačuje, že konkurence v oblasti správy dat se jen zrychlí, což přinese výhody organizacím, které potřebují jednotné a robustní datové systémy.
Na závěr lze říci, že nejlepší architektura závisí na jedinečných potřebách vaší organizace – ať už se jedná o spolehlivost tradičních datových skladů, široké možnosti datových jezer nebo slibnou flexibilitu lakehousů.

