
Keboola transformace – v hlavní roli proměnné | Mňamka #432
V BizzTreatu se staráme o jeden parádní projekt, který musíme udržovat téměř identický pro více regionálních mutací. Jádro nápočtů tak zůstává stejné, ale občas se liší důležité parametry, které jsou specifické pro danou zemi. Jak to řešíme? Od hardcodění jsme se přesunuli k hojnému využívání proměnných, které nám dodávají potřebný manipulační prostor a zároveň nám usnadňují správu kódu.
Proměnné v Keboole
Při práci v SQL transformacích v Keboole můžeme narazit na dva typy proměnných - ty keboolácké a ty snowflakové. Pojďme se na ně podívat.
Keboola proměnné
Proměnné definované v části předcházejícím bloku transformací nejsou vázané na kód transformací samotný. V praxi to znamená, že se nechovají přesně jako proměnné SQL nebo Pythonu - transformační proměnné jsou vyhodnoceny a definovány už před spuštěním transformace a jsou platné pro celou dobu běhu jobu dané konfigurace.
Pro zápis využívají moustache variable syntax a definují se v bloku “Variables” předcházejícím script samotný a následně se v kódu vkládá název proměnné do dvojitých složených závorek . Více v Keboola dokumentaci.
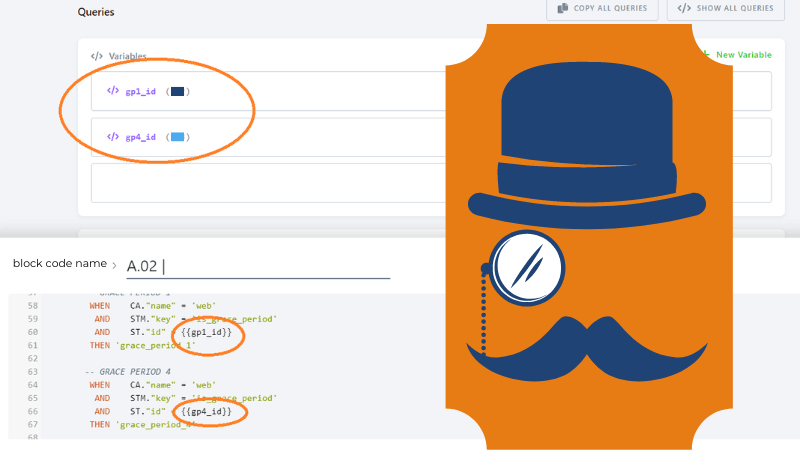
Samozřejmě záleží, jakou hodnotu potřebujete vložit do proměnné, ale odpovídá to běžné SQL syntaxi - stringy v jednoduchých uvozovkách, integery bez, pokud potřebujete vložit seznam hodnot, tak se vkládá jako [value1,value2] (tj. bez jednoduchých uvozovek a mezer).

Snowflake proměnné
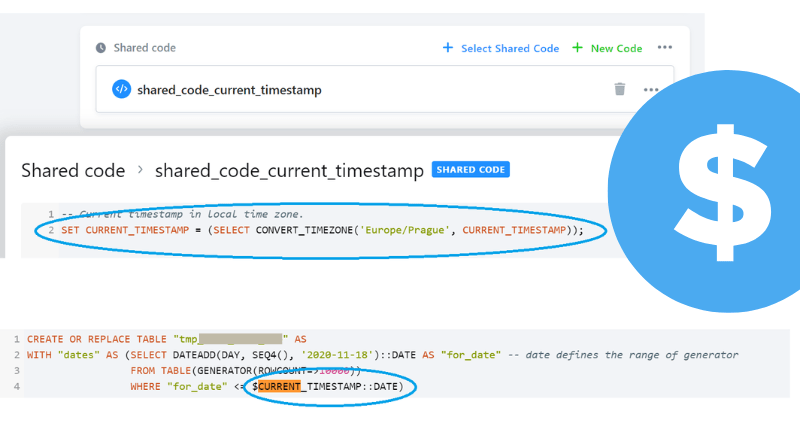
Tento druhý typ proměnných se definuje přímo v kódu a díky tomu také zůstává jeho součástí a platí po dobu celého jobu, kdy běží transformace. Best practice je nadefinovat si je na začátku kódu, ideálně, pokud je využíváte napříč celým Keboola projektem, tak využít i shared code. Takto definované proměnné se pak v kódu používají předsazené znakem dolaru $ .
Co, kdy a jak používat?
Pro co nejpohodlnější vývoj je ideální použít kombinaci zmíněných proměnných. Pokud si totiž nejdřív nadefinujete Keboola proměnné v záhlaví transformací a pak hned v úvodním bloku si je převedete na Snowflake proměnné, tak při zkopírování celé transformace do vývojového workspace stačí vyplnit hodnoty proměnných pouze na jednom místě, a ne na všech možných i nemožných místech, kam jste v rámci vývoje danou proměnnou umístili. Je to funkční, praktické a elegantní.
Jak na to krok za krokem?
- definovat proměnné v KBC transformaci (tj. v části “Variables”)
- pomocí SET přiřadit hodnotu Keboola proměnné Snowflake proměnné
- používat Snowflake proměnnou v kódu
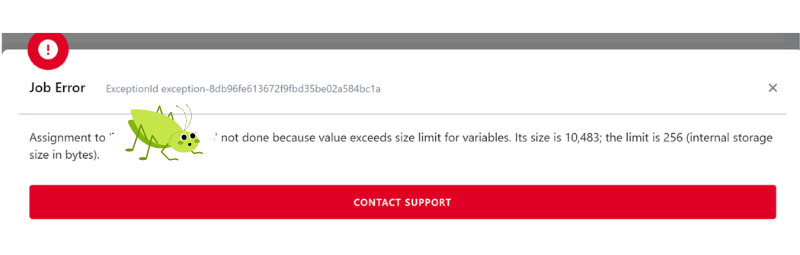
Nic ovšem není dokonalé - proměnné ve Snowflake jsou limitované. Jak praví Snowflake dokumentace - maximální velikost proměnné je limitována na 256 bytes. Pokud tedy potřebujete využít proměnné delší než 256 bytes, tak musíte zůstat u KBC proměnných, které omezené nejsou.
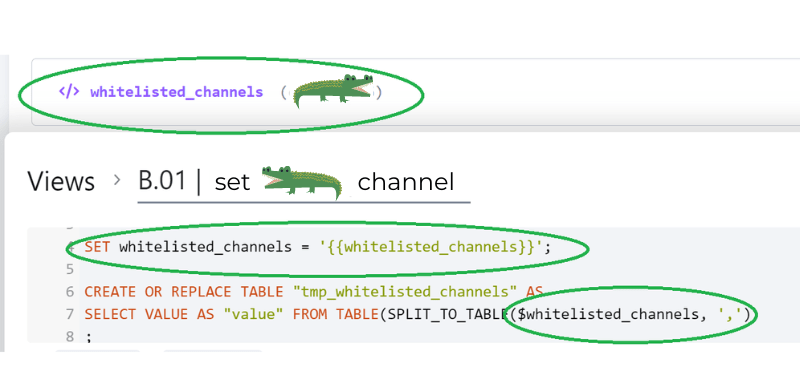
Tím se pak snadno můžete dostat do situace, kdy v KBC budete mít jako proměnnou definovaný dlouhý seznam hodnot. Co s tím pak ve Snowflake?
- KBC proměnnou definovat jako seznam v hranatých závorkách, bez uvozovek kolem hodnot, bez mezer, pouze oddělit čárkami
</> paid_subscription_type ([ value1,value2,value3,value4,value5 ])
- na začátku kódu definovat SQL proměnnou pomocí SET
SET paid_subscription_type = ''
- v kódu je pak nutné parsovat pomocí:
(SELECT VALUE FROM TABLE(FLATTEN(INPUT => PARSE_JSON($paid_subscription_type))))
Podrobný návod pak najdete na Snowflake forum.
Tak, a to je celé. Pokud máte projekt takto pěkně uklizený, tak pak už není problém dosadit do připravené struktury nové proměnné unikátní pro sesterský projekt a ušetřený čas můžete strávit třeba u kafe. ;)


7 signálů, že vaše firma potřebuje datovou strategii | Mňamka #555
Každá firma chce zvednout efektivitu a využít příležitosti, které dnes AI nabízí. Jenže než nasadíte jakýkoliv model, copilota nebo „chytrou analýzu", musíte mít v pořádku to, na čem AI stojí a to jsou pevné datové základy. Následující signály jsou věci, se kterými se u klientů stále poměrně často setkáváme. Pokud některý z nich zní povědomě, datová strategie není nice-to-have. Je to základ. A ten se bohužel nedá přeskočit, i když by to bylo hodně pohodlné. Dá se oddálit, ale pak se vždy platí i s úroky.

EU AI Act: Co to reálně znamená pro české firmy | Mňamka #554
Evropská unie přichází s první ucelenou regulací umělé inteligence. EU AI Act má nastavit pravidla pro to, jak se AI vyvíjí a používá. Pro spoustu firem to může znít jako další regulace navíc. Ve skutečnosti ale jde o změnu, která se poměrně rychle propíše do každodenního fungování. AI už dávno není jen experiment nebo playground pro technologické firmy a čím víc se AI dostává do citlivých oblastí, tím větší tlak je na to, aby její fungování bylo férové a kontrolovatelné. Jak se tato regulace dotkne českých firem a co je v této regulaci podstatné?

Google Workspaces - Přestaňte platit za centrální správu podpisů v Gmailu | Mňamka #553
Přišli jsme o správu e-mailových podpisů při přechodu k novému GCP partnerovi. Místo placení SaaS nástrojů jsem to postavil za odpoledne přes Google Apps Script – zdarma. Tady je celý návod.
